Last Updated 2011/09/21
私は当初、サロゲートペアに興味がありませんでしたが、XPS の研究を始めてみると無視できないことが分かりました。そこで、XPS のページに含めることにしたのですが、.Net Framework 全般に関わる問題であることは言うまでもありません。
【注意】
このページの一部の文字はサロゲートペアを使っていますので、IE(インターネットエクスプローラ)でなければ正しく表示されない場合があります。
サロゲート "surrogate" の英語としての意味は、「代理人」とか「代用物」です。これだけでは何のことかサッパリですが、日本語にしにくい言葉ではあります。
2009 年に「サロゲート」というタイトルの、ブルースウイルス主演のアメリカ映画が公開されました。そこでは、人間の代わりに仕事をするロボット(いわゆる、ミュータント)の意味で使っています。
さて、サロゲートについて語るには Unicode の話から始めなければなりません。
Unicode は一つの文字を 16 ビット(2 バイト)のコードであらわせば、2 の 16 乗、つまり、65,536 個の文字を表現できるので、世界中の文字をカバーすることができるという発想から考案されたものです。しかし、残念ながらアメリカ人にはヨーロッパ語だけしか目に入らなかったと見えます。
英語であればわずか 7 ビットですべての文字を表現できます。インターネットの世界では送信時の手順が 7 ビットになっているのもそこに起因します。日本語の半角カナが使えないのは、半角カナは 8 ビットを使わなければならないからにほかなりません。蛇足ですが、日本語をあらわすときの文字コードの shift-jis は 8 ビット必要ですが、JIS コードは 7 ビットですので、メールなどでは JIS コードを使うことで日本語を扱えます。
Unicode の普及とともに、残っている空き領域を利用する要求が高まり、16 ビットで表現する文字を 2 つ使って新しい 1 つの文字を定義するという手法が導入されました。これがサロゲートペアです。
サロゲートペアは空き領域の U+D800 〜 U+DFFF までを使うことにし、前半の U+D800 〜 U+DBFF の範囲を上位サロゲート、後半の U+DC00 〜 U+DFFF を下位サロゲートと呼びます。それぞれ、1,024 個あるので、1,024 x 1,024 = 1,047,576 個の文字を新しく定義可能となります。サロゲートペアを利用することで、わずか 65,536 から大幅に増えたというわけです。
なお、文字列の中にサロゲートペアを含む場合、従来の String クラスでは正しく扱うことができない場合があります。たとえば、Length プロパティは 2 バイトで 1 文字として計算するので、サロゲートペアを含む文字列に対しては正しい結果を返しません。そこで、.Net Framework では別の仕組みを用意しました。詳しくは、.Net Framework クラスライブラリリファレンスを参照してください。
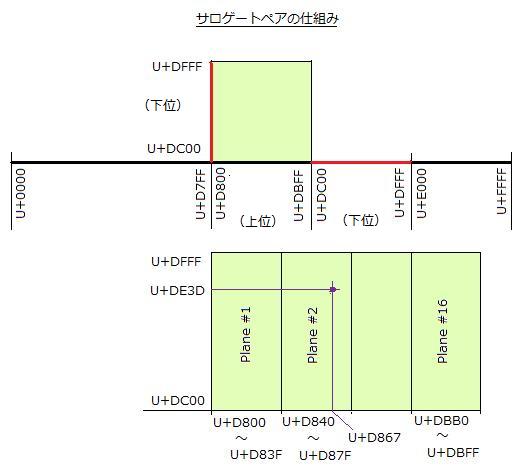
サロゲートペアは上位サロゲートと下位サロゲートとの組み合わせですが、そのあたりの状況を図示してみましょう。下位サロゲートの U+DC00 〜 U+DFFF の範囲を Y 軸方向に移動するとサロゲートペアの仕組みが分かりやすくなります。下図の赤線で示した部分です。下図の下側は、関連する部分を拡大表示したものです。上位サロゲートの U+D867、下位サロゲートの U+DE3D は魚偏に花の「��」で、「ホッケ」をあらわすサロゲートペアです。これは Plane #2 にあり、Unicode コードポイントは U+29E3D です。
このページを IE 以外で表示している場合、上記の文章の一部が文字化けしているかもしれません。
「サロゲートペアの仕組み」は、サロゲートペアだけについて説明しましたが、この項ではサロゲートペアと Unicode コードポイントとの関連について説明します。
「サロゲートペアの仕組み」では触れませんでしたが、従来の 16 ビット値の範囲は Plane #0 にあたります。従来のサロゲートペアでない文字はすべてこの範囲に含まれますので、「基本多言語面」と名付けられています。Plane #1 は「追加多言語面」と呼びますが、日本語では使っていないようです。日本語対応のサロゲートペアは Plane #2 にあります。

さて、サロゲートペアから Unicode コードポイントを取得する機能が .Net Framework にはありません。そこで、作ってみました。コード内に出てくるクラスなどの説明は WPF クラスライブラリリファレンスを参照してください。
// GetUnicodePointFromSurrogate メソッドの使い方
private void button1_Click(object sender, RoutedEventArgs e)
{
GlyphTypeface typeface = new GlyphTypeface(new Uri(@"c:\windows\fonts\meiryo.ttc"));
// 魚偏に花の「ホッケ」
ushort lead = 0xD867;
ushort trail = 0xDE3D;
int index = this.GetUnicodePointFromSurrogate(lead, trail);
IDictionary<int, ushort> dic = typeface.CharacterToGlyphMap;
ushort glyphIndex = dic[index];
Title = String.Format("{0:X} {1}", index, glyphIndex);
// 実行結果: 29E3D 20679
}
//-----------------------------------------------------------------------------------
// サロゲートペアに対応する Unicode コードポイントを取得する
// lead : 上位サロゲート
// trail : 下位サロゲート
private int GetUnicodePointFromSurrogate(ushort lead, ushort trail)
{
int plane = ((lead - 0xD800) / 0x0040) + 1;
int lead2 = lead - (0xD800 + 0x0040 * (plane - 1));
int trail2 = trail - 0xDC00;
return (plane * 0x10000 + lead2 * 0x100 + lead2 * 0x300 + trail2);
}
サロゲートペア導入以前の Unicode コードポイントは 16 ビット値(ushort 型)でしたが、サロゲートペア導入後は 21 ビット値になりました。したがって、int 型です。16 〜 20 ビットには Plane "面" を指定します。サロゲートでない文字の Plane は 0 で、下図では「あ」のケースを示します。サロゲートペアの「���」の Unicode コードポイントは U+29E3D で、Plane #2 にあります。
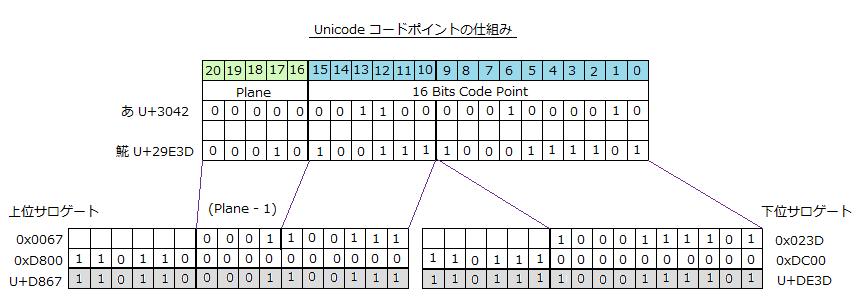
上図の下部は Unicode コードポイントと上位および下位サロゲートとのビットの構成を示します。Plane は 16 あるので、16 をあらわすために 5 ビット必要です。(Plane - 1) は Plane の番号から 1 を差し引いた数値という意味です。つまり、Plane #1 は 0、Plane # は 1 になりますので、0 〜 15 をあらわすには 4 ビットあれば間に合います。こうすることで、上位サロゲートをあらわす 0xD800 からのオフセットを 10 ビットで表現できるので、全体で 16 ビットとなりピッタリというわけです。実にうまくできていますね。
下位サロゲートも同様に、0xDC00 からのオフセットが 0x023D ですから全体で U+DE3D になります。
さて、「Unicode コードポイントの構成」ではサロゲートペアから Unicode コードポイントを取得するメソッドを紹介しましたが、ここでは逆に Unicode コードポイントからサロゲートペアを取得するメソッドを紹介します。
//-----------------------------------------------------------------------------------
// Unicode コードポイントからサロゲートペアを取得する
// codePoint : Unicode コードポイント
private ushort[] GetSurrogatePairFromUnicodePoint(int codePoint)
{
int plane = codePoint >> 16;
int lead2 = ((codePoint >> 10) & 0x3F) + 0xD800 + 0x0040 * (plane - 1);
int trail2 = (codePoint & 0x3FF) + 0xDC00;
return (new ushort[2] { (ushort)lead2, (ushort)trail2});
}
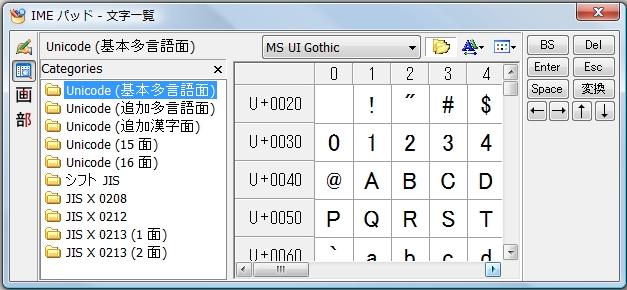
ところで、現在の IME の機能ではサロゲートペアを入力することができません。しかし、手段は提供されています。Windows 付属の NotePad.exe または WordPad.exe を起動してください。次に、ツールバーにある [IME]-[IME パッド] を選択してください。下図は IME パッドを起動したところです。フォントの種類を指定し、画面左側にある [Categories]-[Unicode(追加漢字面)] を選択すると、サロゲートペアが右側に表示されます。適当な文字を選択すると、現在キャレットのある位置にコピーされます。
詳しくは知りませんが、アラビア語では 2 つの文字を結合して 1 つの文字として表現することがあるそうです。似たものが日本語にもあります。たとえば、カタカナの「パ」は「ハ」に「゚」を結合したものという表現も可能です。
「サロゲートペアを入力する」の記事の続きですが、WordPad.exe において、カタカナの「ハ」を入力したあと、IME パッドの [Categories]-[Unicode(基本多言語面)]-[ひらがな] を選択し、U+309A をクリックすると、「゚」が入力されます。ただし、すでに入力済みの「ハ」と結合し、「パ」になるはずです。ちなみに、NotePad.exe のほうはこうはなりません。
テキストエディタの中にはサロゲートペア自体はサポートしても、結合文字をサポートするものとしないものとがあります。「パ」を結合文字を使って入力する人はいないかもしれませんが、手段として可能である以上、その可能性を排除することはできません。
TextBox、TextBlock、Label コントロールにサロゲートペアを含む文字列をコードを使って設定する場合、次のようなコードで可能です。「��」の部分は IME パッドを使えば入力できます。
textBox1.Text = "\uD867\uDE3D" + " ��";
次は、XAML コードの場合です。特殊文字と同じ扱い方にしなければなりませんので、サロゲートペアを指定する方法が異なります。
<TextBlock Name="textBlock1" Width="260">�� ��</TextBlock>
もう一つ、あります。XPS ドキュメント内のテキストにおいてサロゲートペアを使う場合です。この場合、Glyphs クラスの UnicodeString プロパティには Unicode コードポイントを指定しなければなりません。また、Indices プロパティには Unicode コードポイントに対応するグリフインデックスを指定します。さらに、サロゲートペアは 2 文字ですからそれを 1 文字に変換するため、チョットしたおまじないが必要です。ちなみに、この場合は UnicodeString プロパティの設定を省略、または空の文字列を指定することもできます。UnicodeString プロパティを設定しない場合は、Indices="20679" だけでかまいません。
<Glyphs Fill="#FF000000" FontUri="c:/Windows/Fonts/meiryo.ttc"
FontRenderingEmSize="24" StyleSimulations="None"
OriginX="0" OriginY="30" UnicodeString="𩸽" Indices="(2:1)20679">
</Glyphs>
「サロゲートペアを含む文字列をコードで設定する」の項で、Glyphs クラスの Indices プロパティについて触れました。これには物理フォントのグリフインデックスを設定しなければなりません。サロゲートペアではない文字に対するグリフインデックスを取得する手順は WPF に中にありますので、メソッドの形式にしておきました。
// 文字に対応するグリフインデックスを取得する
// glyphTypeface : GlyphTypeface オブジェクト
// c : 文字(サロゲートペアは指定できない)
private ushort GetGlyphIndexFromCharacter(GlyphTypeface glyphTypeface, char c)
{
ushort index = 0;
glyphTypeface.CharacterToGlyphMap.TryGetValue(c, out index);
return index;
}
次に、サロゲートペアを含む場合です。サロゲートペアから Unicode コードポイントを取得し、それに対応するグリフインデックスを取得します。以下のコードは「Unicode コードポイントの構成」の項と同じものです。
private void button1_Click(object sender, RoutedEventArgs e)
{
GlyphTypeface typeface = new GlyphTypeface(new Uri(@"c:\windows\fonts\meiryo.ttc"));
// 魚偏に花の「��」
ushort lead = 0xD867;
ushort trail = 0xDE3D;
int index = this.GetUnicodePointFromSurrogate(lead, trail);
IDictionary<int, ushort> dic = typeface.CharacterToGlyphMap;
ushort glyphIndex = dic[index];
Title = String.Format("{0:X} {1}", index, glyphIndex);
// 実行結果: 29E3D 20679
}
サロゲートペアを含む文字列に対して、String クラスの Length プロパティを適用しても正しい結果を得ることはできません。このような機能を補完するために、.Net Framework ではいくつかのクラスを提供しています。System.Globalization.StringInfo および System.Globalization.CharUnicodeInfo クラスです。ただし、あまりアリガタイ機能はありません。詳しくは、.Net Framework クラスライブラリリファレンスの「文字と文字列」-「ストリング情報」を参照してください。
チョット雑ですが、メソッドにしてみました。要するに、文字列の文字数をチェックするだけです。
// 指定の文字列がサロゲートペアを含むかどうかをチェックする
private bool IsIncludedSurrogatePair(string s)
{
int length = s.Length;
System.Globalization.StringInfo info = new System.Globalization.StringInfo(s);
int length2 = info.LengthInTextElements;
return (length != length2);
}
−以上−